
오토 인코더(Auto encoder)
- 비지도 학습 방법론에서 주로 사용 되는 구조
- 비지도 학습은 데이터의 숨겨진 특징이나 구조를 발견하는데 사용
- 출력값을 입력값의 근사로 하는 함수를 학습
- 인코더를 통해 입력 데이터에 대한 특징을 추출하고, 디코더를 통해 원본 데이터를 재구성 하는 방식
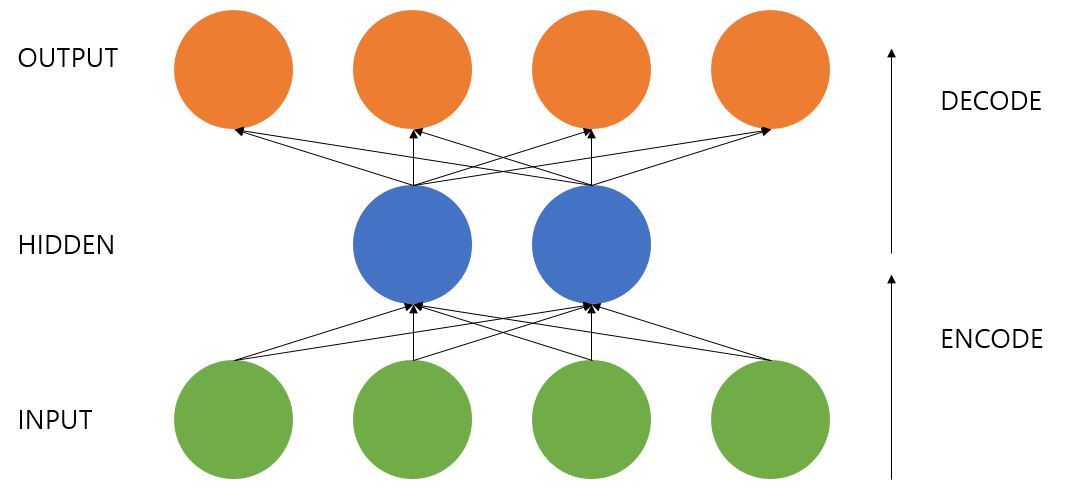
오토 인코더는 하나의 히든 레이어가 있는 신경망인데 입력값이 그대로 출력값이 된다. 이때 히든 레이어가 입력값을 압축하여 특징값을 추출할 수 있다.
원리
- 인코딩 과정에서 입력된 데이터의 핵심 특징을 히든 레이어에서 학습, 나머지는 손실되게 한다
- 디코딩 과정에서 입력값의 근사값을 출력한다(입력 값의 복사가 아닌 비슷한 값을 출력)
학습 과정
- 입력값과 히든 레이어의 가중치를 계산하여
sigmoid함수를 통과 - 이전의 결과물과 출력 레이어의 가중치를 계산해
sigmoid함수를 통과 - MSE 계산
- Loss를
SGD를 이용한 최적화 backprop를 사용하여 가중치를 갱신
예제 소스코드
출처: golbin tensorflow (골빈)
# 대표적인 비지도(Unsupervised) 학습 방법인 Autoencoder 를 구현해봅니다.
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("./mnist/data/", one_hot=True)
#########
# 옵션 설정
######
learning_rate = 0.01
training_epoch = 20
batch_size = 100
# 신경망 레이어 구성 옵션
n_hidden = 256 # 히든 레이어의 뉴런 갯수
n_input = 28*28 # 입력값 크기 - 이미지 픽셀수
#########
# 신경망 모델 구성
######
# Y 가 없습니다. 입력값을 Y로 사용하기 때문입니다.
X = tf.placeholder(tf.float32, [None, n_input])
# 인코더 레이어와 디코더 레이어의 가중치와 편향 변수를 설정합니다.
# 다음과 같이 이어지는 레이어를 구성하기 위한 값들 입니다.
# input -> encode -> decode -> output
W_encode = tf.Variable(tf.random_normal([n_input, n_hidden]))
b_encode = tf.Variable(tf.random_normal([n_hidden]))
# sigmoid 함수를 이용해 신경망 레이어를 구성합니다.
# sigmoid(X * W + b)
# 인코더 레이어 구성
encoder = tf.nn.sigmoid(
tf.add(tf.matmul(X, W_encode), b_encode))
# encode 의 아웃풋 크기를 입력값보다 작은 크기로 만들어 정보를 압축하여 특성을 뽑아내고,
# decode 의 출력을 입력값과 동일한 크기를 갖도록하여 입력과 똑같은 아웃풋을 만들어 내도록 합니다.
# 히든 레이어의 구성과 특성치을 뽑아내는 알고리즘을 변경하여 다양한 오토인코더를 만들 수 있습니다.
W_decode = tf.Variable(tf.random_normal([n_hidden, n_input]))
b_decode = tf.Variable(tf.random_normal([n_input]))
# 디코더 레이어 구성
# 이 디코더가 최종 모델이 됩니다.
decoder = tf.nn.sigmoid(
tf.add(tf.matmul(encoder, W_decode), b_decode))
# 디코더는 인풋과 최대한 같은 결과를 내야 하므로, 디코딩한 결과를 평가하기 위해
# 입력 값인 X 값을 평가를 위한 실측 결과 값으로하여 decoder 와의 차이를 손실값으로 설정합니다.
cost = tf.reduce_mean(tf.pow(X - decoder, 2))
optimizer = tf.train.RMSPropOptimizer(learning_rate).minimize(cost)
#########
# 신경망 모델 학습
######
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
total_batch = int(mnist.train.num_examples/batch_size)
for epoch in range(training_epoch):
total_cost = 0
for i in range(total_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
_, cost_val = sess.run([optimizer, cost],
feed_dict={X: batch_xs})
total_cost += cost_val
print('Epoch:', '%04d' % (epoch + 1),
'Avg. cost =', '{:.4f}'.format(total_cost / total_batch))
print('최적화 완료!')
#########
# 결과 확인
# 입력값(위쪽)과 모델이 생성한 값(아래쪽)을 시각적으로 비교해봅니다.
######
sample_size = 10
samples = sess.run(decoder,
feed_dict={X: mnist.test.images[:sample_size]})
fig, ax = plt.subplots(2, sample_size, figsize=(sample_size, 2))
for i in range(sample_size):
ax[0][i].set_axis_off()
ax[1][i].set_axis_off()
ax[0][i].imshow(np.reshape(mnist.test.images[i], (28, 28)))
ax[1][i].imshow(np.reshape(samples[i], (28, 28)))
plt.show()